在人工智能领域,语音合成技术(Text-to-Speech,简称 TTS)一直是研究的热点方向之一。早期的TTS主要应用于特定场景下的语音播报,比如火车站的到站通知、气象预报等。虽然可以完成基本的文本到语音的转换,但合成的语音往往机械、生硬,缺乏自然度和表现力。随着技术的进步,TTS 在智能客服、数字人播报、有声读物、导航系统等领域得到广泛应用,极大地改善了人机交互体验。 现在随着大模型应用场景越来越多样,大家除文本外其他模态的需求也越来越多。就语音合成的要求也越来越多样,比如伴随着LLM 流式输出,语音如何更低延迟的输出,比如如何用几秒的短音频复刻一个相似度极高的合成声音,比如在不同的应用场景的下语音合成的情感表现度能否根据文本语义更契合等等
语音合成评估关注什么?
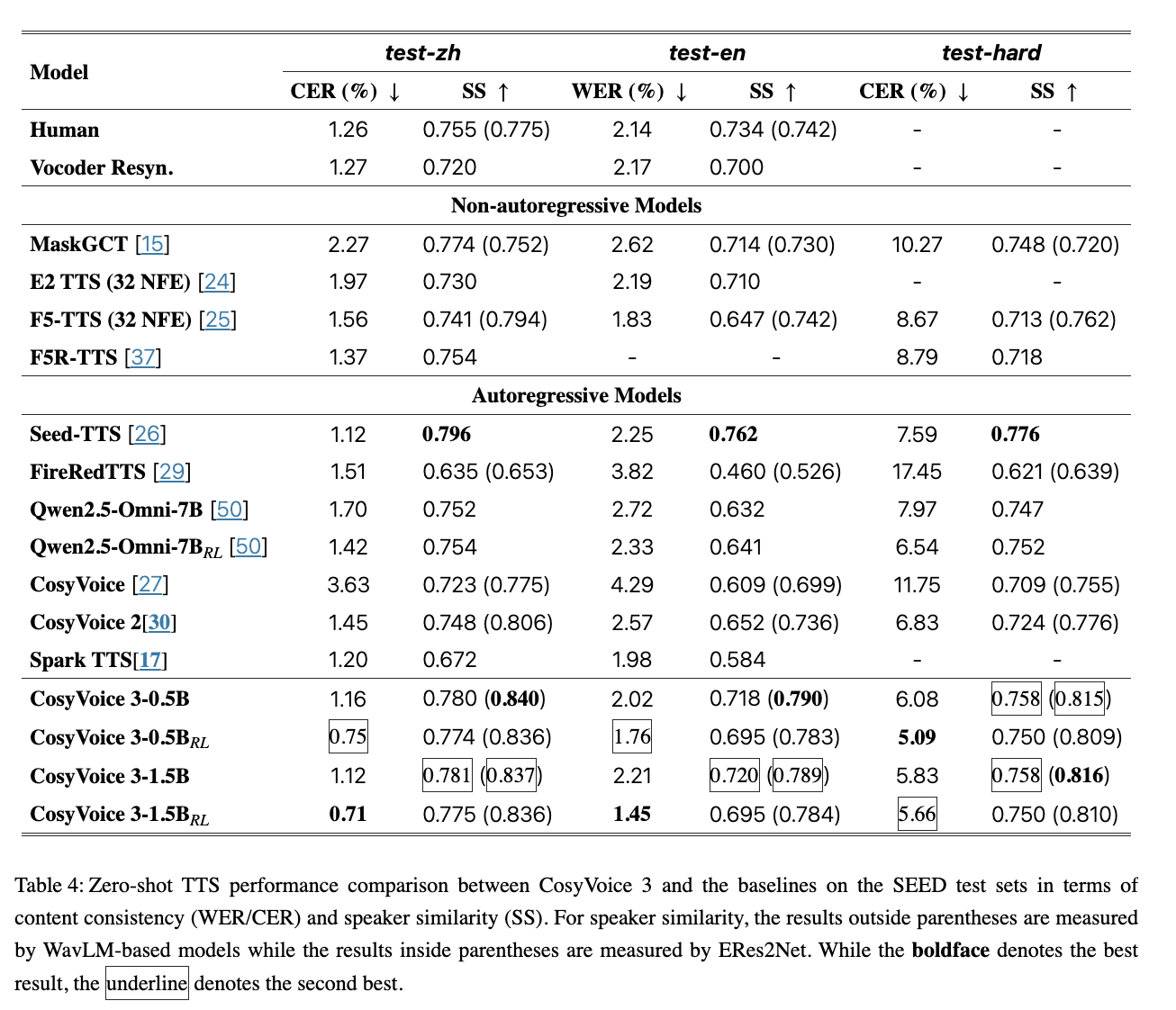
这里我们以 CosyVoice3最新的 tech report 米说明语音合成模型的评估具体是怎么做的,这对业务方自己在测试语音合成模型效果也有一定参考性。CosyVoice 3 对于 zero-shot 的语音合成能力,重点关注以下三个方面
- Content Consistecy: focus on Character Error Rate (CER) or Word Error Rate(WER),即就是将语音合成的内容通过语音识别模型转为文本,之后再将转录后的文本和语音输出的原始文本内容做字词级别的错误率比较。这里 CosyVoice3 的团队英文 ASR 选择 OpenAI 的 Whisper-Large V3,中文 ASR选择自家之前开源的 Paraformer
- Speaker Similarity:使用 ERes2Net 模型(说话人识别模型[一般包含说话人识别和说话人验证,这里用到说话人验证])从生成的音频中抽取 Speaker embedding,计算生成的音频和参考音频之间的 cosine 相似度;这里依赖于Speaker verification model 的能力,算是半客观的一个评估方式。
- Audio Quality:使用 DNSMOS network 对合成的音频做打分(和人的听觉感知强相关)
在测试集选择时,CosyVoice 团队选择广泛使用的 SEED-TTS-Eval 来抽取普通话,英文以及 hard Chinese subsets 的测试样例。这里为了保证对比的公平和理性,还使用 WavLM-based speaker recognition model 计算 speaker similarity。
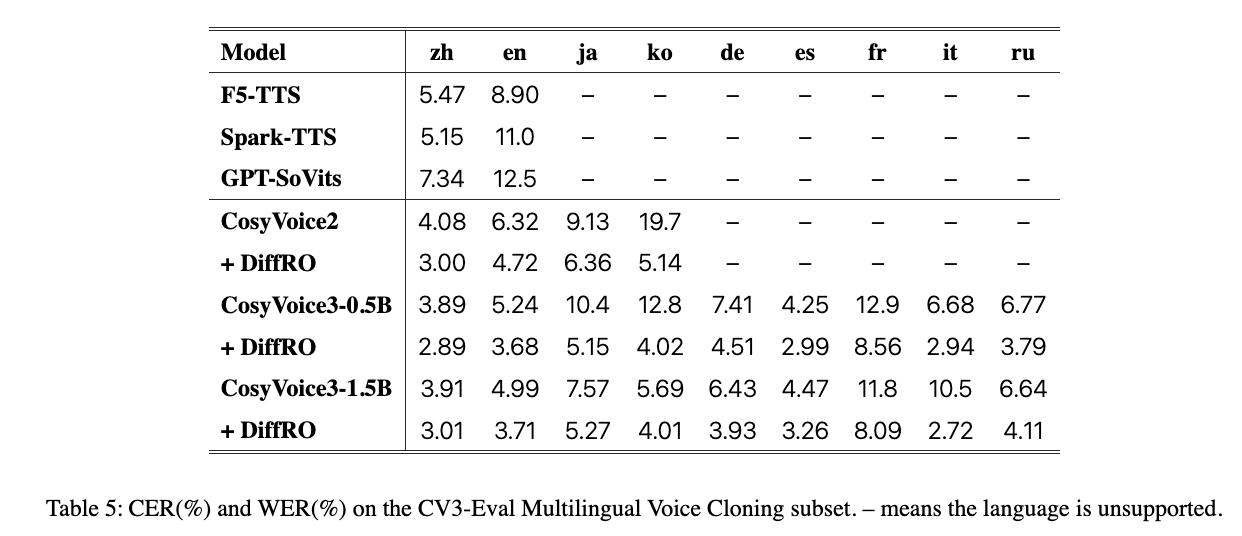
由于近期最新的模型在这个测试集中表现都很接近,提升空间有限。为了更全面的评估 CosyVoce3,作者还新提出一个多语言 benchmarkCV3-Eval,包含以下客观和主观的评估项
- Objective Evaluation
- Multilingual Voice Cloning:包含中英日韩德法意西俄九个语种,尽可能多的模拟真实世界的应用场景
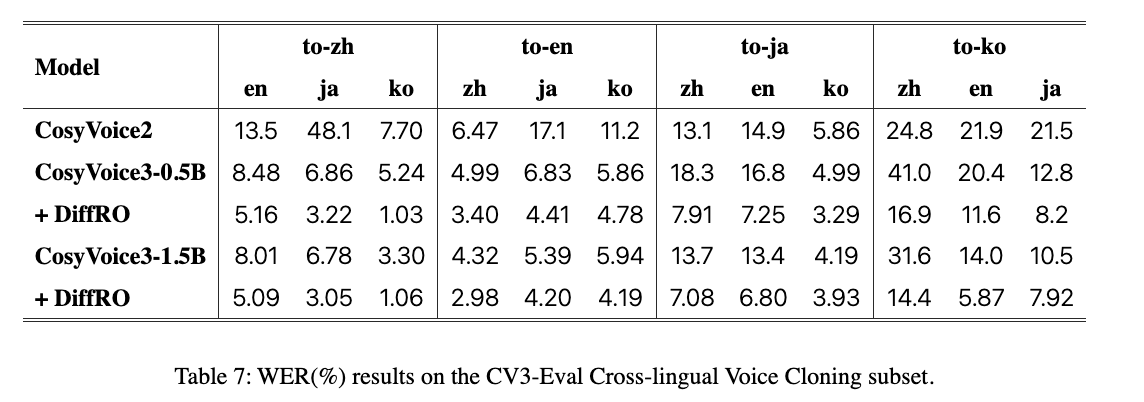
- Cross-lingual Voice Cloning:跨语言声音克隆能力,比如参考音频内容是中文,之后合成的内容是英文Emotion Cloning:主要是中英语种样例,文本会有对应的情绪标签(比如高兴,伤心,生气等),这块儿进一步的还对文本内容本身和情绪标签是否有关作分类,以确定合成音频的情绪主要来自文本内容还是提示音频。
- Subjective Evaluation
- Expressive Voice Cloning:任务包含有新闻,播客,电视剧等多样化场景,设计了不同的语音生成提示,比如情绪激烈的语调,耳语或者是嘶吼,以及极慢或者是极快的语速等。
- Expressive Voice Continuation:由于人的感知具有很大的变异性,要对富有表现力的语音克隆进行公平的主观评价具有挑战性,为了公平性,从网站上选取 120 个不同情绪、节奏、速度和音量的音频样本,并剪切音频片段的前 3 秒作为提示语音,再基于合成的剩余语音评估和参考音频的相似度
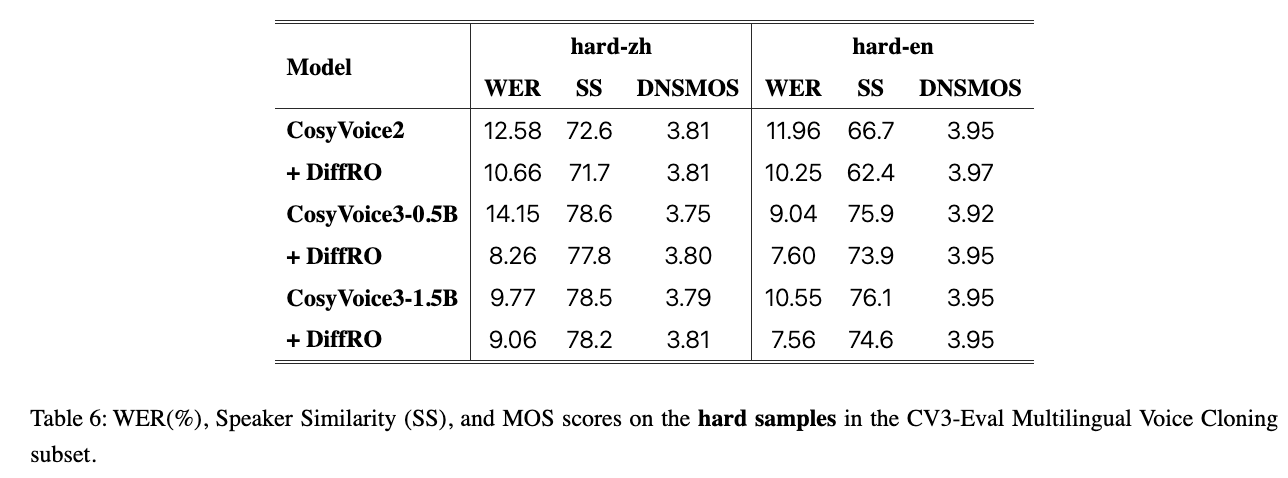
- Chinese Accent Voice Cloning:中文方言口音的评估,主要是内部的数据集,包含18种不同的方
评测结果
Results of Multilingual Voice Cloning
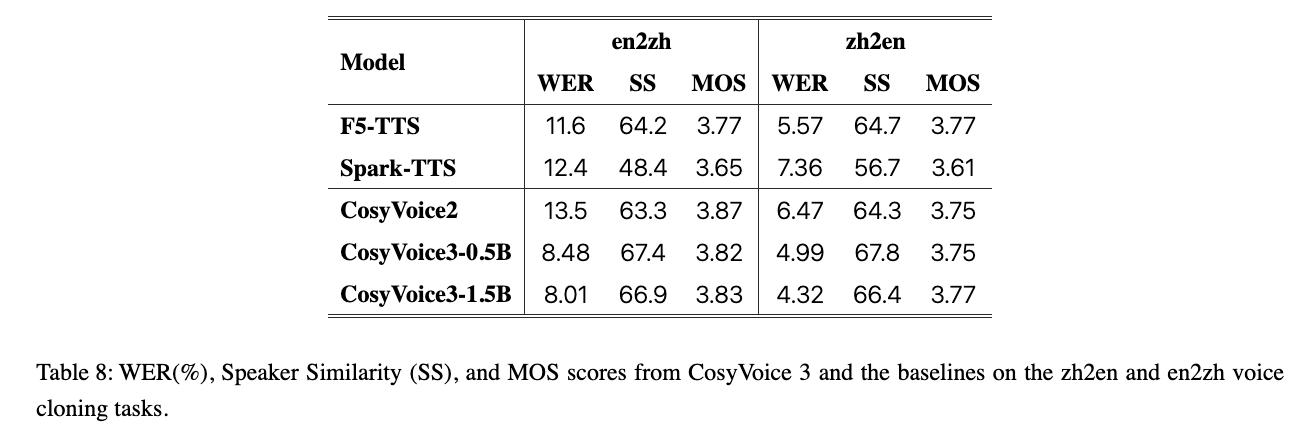
下面是 Cosyvoice3 和其他模型的评测对比,主要是 Content Consistecy 和 SpeakerSimilarity 评估:
对于中英语种 hard sample 的三个维度评估结果:
Result of Cross-lingual Voice Cloning
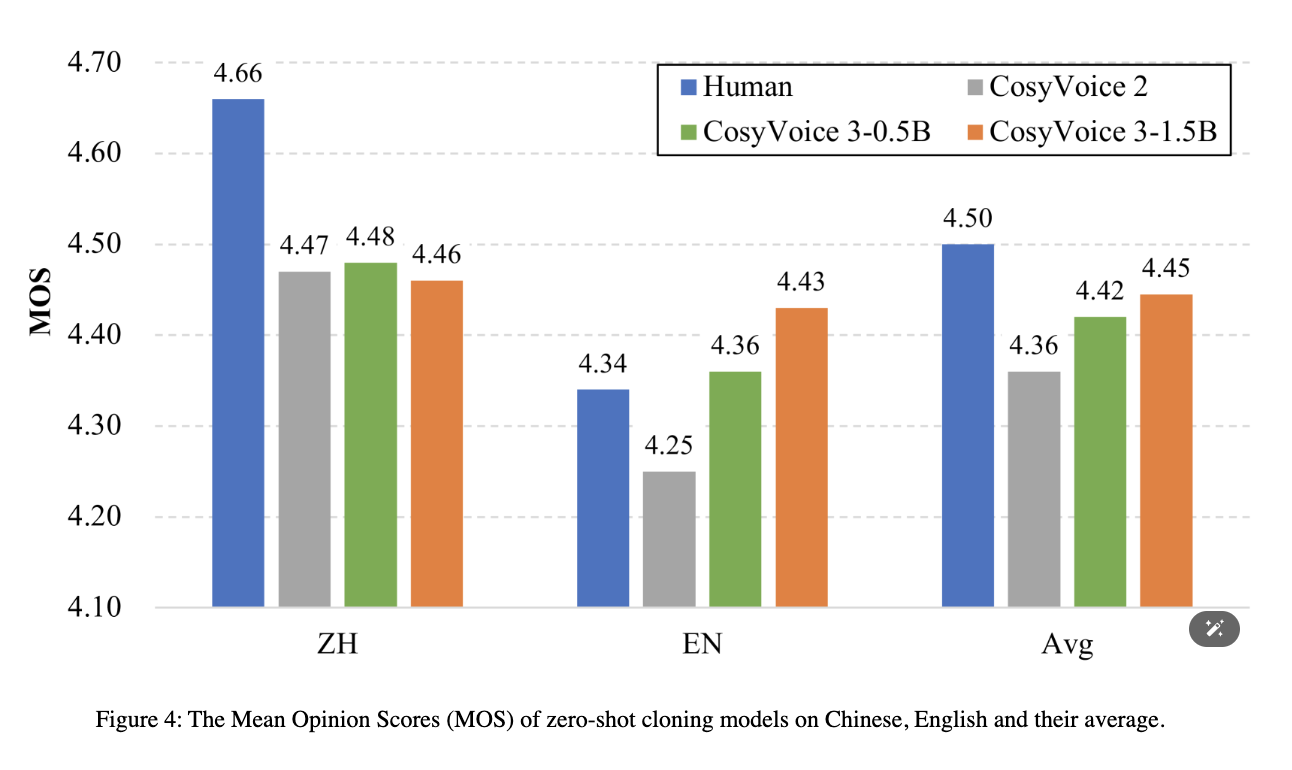 这里使用 Mean Opinion Scores(MOS) 做主观评价。测试样本包括 200 个中英文句子,每个句子由 10 名母语人士(5男5 女)进行评估。分数从1 到5不等,以0.5 分递增。图 4显示了 CosyVoice 2、CosyVoice3-0.5B 和 CosyVoice3-1.5B 三种型号在两种语言中的 MOS 分数及其平均分。
这里使用 Mean Opinion Scores(MOS) 做主观评价。测试样本包括 200 个中英文句子,每个句子由 10 名母语人士(5男5 女)进行评估。分数从1 到5不等,以0.5 分递增。图 4显示了 CosyVoice 2、CosyVoice3-0.5B 和 CosyVoice3-1.5B 三种型号在两种语言中的 MOS 分数及其平均分。
在中文方面,三种模式的表现相似,但仍落后于人类语音。在英语方面,CosyVoice 2 的得分低于人类基准,CosyVoice 3-0.5B的得分与人类基准相当,而 CosyVoice 3-1.5B 的得分明显高于人类基准。总体而言,CosyVoice 3-1.5B 优于 CosyVoice 3-0.5B,两者都超过了 CosyVoice 2,这说明了数据和模型扩展的优势。 尽管 CosyVoice 3 模型的中文语音与人类语音存在一些差异,但其得分仍高于 4.45。造成这一差距的主要原因是合成输出与真实语音相比存在一些低分情况,这表明在今后的工作中需要提高合成的稳定性。
业务方一般怎么选 TTS?
- 应用产品团队在选择合适的语音模型时通常都会明确需求,也就是先清晰的定义使用场景,目标用户,以及核心需求(比如必须满足什么,优先优化什么)。比如一个直播应用,做一个主播分身代替真人 24h 开播,这里对于声音合成的要求就是要很像主播真人,自然流畅,需要能支持流式合成,延迟要尽可能的低接近真人反应速度,ta 的主要受众就是主播原有的粉丝,或是从虚拟主播推荐页点进来的路人
- 产品方案调研:比如国内主流的云服务商(阿里,火山,腾讯等),语音方面积淀颇深的科大讯飞,六小虎里的 minimax,海外 AWS, Google, ElevenLabs 等,或者是技术能力强的团队自研和定制都可以产品集成与可用性 a. 首次播放延迟是否可接受,流式合成能力以及并发的支持度; b. 测试 API/SDK,提供的API 是否清晰、稳定、文档完善,是否易于集成到现有系统,错误处理和日志是否友
- 测试集构建: a. 首先是通用标准类测试集,覆盖短句,长句,复杂长难句等 b. 场景化的测试用例:最好是包含真实的用户数据,比如直播场景可以从过去主播直播间捞数据 c. 评测:客观指标可以是 Content Consistecv (WER),合成速度(延迟,吞吐):内部的主观评测(MOS)是很重要的,可以邀请团队成员(尤其是非技术人员)盲听打分测评,并记录问题:一些场景也可以邀请核心的用户来做评测,这样会更准确
- 成本评估:一般需要计算各种使用量下的成本预算,比如回复或者是播报的文本量
sota 效果的语音合成模型的 size 相较于语言模型都是比较小的,对机器资源的配置要求也不是那么高。但是其 API 收费的价格相对现在大模型 tokens 却没那么便宜,从这个角度讲厂商做语音领域的 ROI 还蛮高的(OS:minimax 在这块儿应该是有体现?)
Appendix
WER/CER 怎么算 • 英文,最小单元是单词,语音识别应该用”字错误率”(WER)。 • 中文,最小单元是字符,语音识别应该用“字符错误率”(CER)。计算公式 WER = (S + D + I) / N= (S + D + I) / (S + D + C) * 100% 公式注解 • S:替换的字数,如 你好呀。被识别为:你好丫。 • D: 删除的字数,如 你好呀。被识别为:你好。 • I:插入的字数,如 你好呀。被识别为:你丫 好呀。 • C: 正确的字数 • N:为(S 替换 +D 删除 +C正确)的字数,需要注意的是这并不等于原句总字数或者识别果字数