背景
最近不少平台都开始支持 LoRA 后的模型按API调用时使用的 token 计费,比如GCP的ai studio,火山方舟等,吸引了很多企业用户在该平台上做微调训练。
这里简单介绍下,什么是 LoRA 微调,以及为什么这种训练方式能够以极低的 token 计费模式推行。
什么是 LoRA
LoRA(Low-Rank Adaptation)是一种用于在预训练模型基础上进行高效微调(Fine-Tuning)的算法。它的核心思想是通过引入低秩矩阵分解的方式,在保持原始预训练模型权重不变的前提下,通过在模型的每个Transformer层中引入可训练的低秩矩阵来适应特定任务,而不是微调所有预训练的权重,从而显著降低微调过程中的计算资源和存储需求,同时避免了在微调过程中可能发生的灾难性遗忘
具体来讲,假定输入为 $1\times M$ 的向量$x$,冻结的原始模型权重为$W_{origin}{M\times N}$,新增的两个矩阵为 LoRA A($W_{loraA}M\times r$) 和 LoRA B($W_{loraB}r\times N$),这里的 $r$ 就是低秩矩阵的维度,一般是远远小于原始权重矩阵的秩。
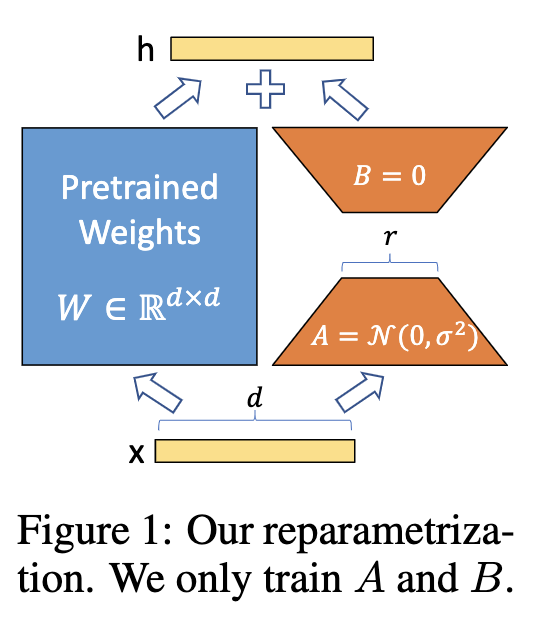
这里我们假定输入和原始权重的输出为 $X$,经过 lora 权重的输出为 $\Delta X$,那么前向传播过程里$X_{Forward}=X+\alpha/r\Delta X$,权重合并时 $W_{Forward}=W_{origin}+\alpha/r\times W_{loraA}\times W_{loraB}$,其中$\alpha$一般是$r$的 2-8 倍
直观感受下LoRA时如何降低训练参数量的:当原始权重矩阵为 $4096\times 4096$时,假设秩$r$为 4,那么原本要更新的参数为$4096\times 4096$,现在是 $4096\times 4$+$4\times 4096$,参数量缩小为原来的 512 倍。
Lora 训练的优点
- 极大的降低微调时的参数量
- 效果接近全参微调
- 推理时模型结构不会改变,LoRA 权重可以与原始模型权重合并,基本不会增加额外的计算开销。
为什么 Lora 微调后可以做到按 token 计费
- 模块化部署动态加载:LoRA 微调的模型,不影响主模型参数,其分解矩阵的适配器可以作为插件灵活加载或卸载,便于在平台上进行多任务部署(对于常驻的租户,可以通过LoRA Merge避免动态加载开销)
- 基础模型资源共享:LoRA adaptor 加载后对推理开销极小,多个用户可以共享同一个基础模型,节省了计算资源
- 精细化竞争:平台可以根据用户实际使用的 token 数量进行计费,避免了传统全参微调按算力单元计费方式的资源浪费